文/新浪财经香港站 赵岚
“先问AI后问医”,当市场教育已经完成,越来越多人在有小病小痛时更倾向于问AI获得即时性答案,而非耗费大量的时间去医院排队就诊。但医疗作为专业性极强的领域,AI问诊真的可靠吗?我们应该以什么标准来评估AI的准确性与专业度?
AI问诊的常用场景:健康管理 慢病管理
市场上医疗类AI大模型及其丰富,当中包括头部大厂的通用大语言模型、健康管理APP、依附于社交软件的小程序等,均可提供问诊类医疗意见。但不同平台给出的答案存在差异,可能导致问诊者困惑,甚至被错误引导。
“AI的回答有时自相矛盾,当我第一次问诊时他会给我推荐几种药,但我第二次补充症状后,他会给我推荐其他几种药,几款药品之间的作用是重叠的,甚至中、西药之间还是相斥的。”有用户表示对AI不信任,由于AI所带的特性会“迎合”用户,即使无法准确判断病情,也会基于有限信息给出模糊或错误的建议。
还有些AI为避免责任风险,回应更像是“精准的废话”,比如机械回复 “遵医嘱”。用户本想获得参考建议,这样的应答完全没有意义。
“现在 AI 不是小众的科技,‘AI+医疗’TO C领域最刚需的场景是健康管理和慢病管理”,德适生物科技(2526.HK)产品负责人何迅对新浪财经表示。
由于AI并不具备如医生般的临床经验,无法针对个体症状与患者进行深度对话,因此用户在问诊时自行提供的信息通常不够全面、缺少关键检测数据,导致AI漏诊概率高。
何迅表示,当前市场端智能体虽然供给充足,但行业发展整体处于粗放增长阶段,产品质量与专业能力较为分化,普通用户可能难以选择。
“市场比较缺乏统一的评价标准与权威机制来考察医疗大模型的可信程度,所以建立了这套医疗 AI 评测榜单体系。”

这套医疗AI评测平台为DoctorBench,为国内机构牵头建立,在香港发布,试图填补行业标准空白,杭州智诊科技WiseDiag-v2、谷歌Gemini-3.1-Pro-Preview、OpenAIGPT-5.4 位列前三。
而在去年5月,OpenAI也发布了医疗评测体系HealthBench,OpenAI o3、GPT-4.1、Claude 3.7 Sonnet位列前三。

中外医疗AI榜单评估标准有色差?
国内医疗AI榜单的发布也引发行业对“医疗AI评估标准”的探讨。
中外医疗体系存在差异,对应的AI评估标准是否也存在“色差”?目前国内建立的评测体系,是否能全面覆盖不同场景下的医疗AI需求?未来如何推动形成国内外认可的统一评估标准?
从两张榜单上榜产品看,头部产品重叠度较高但顺位稍有不同,其他上榜产品具有强烈的“本土化”特征。
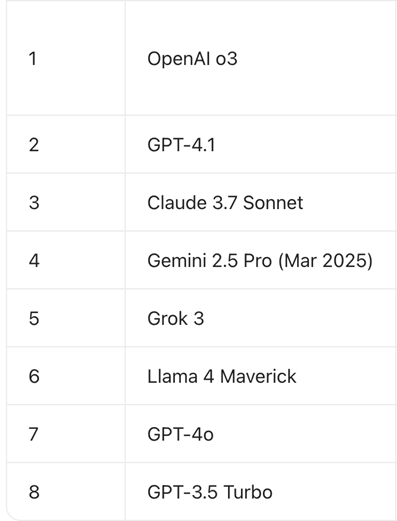 (图为HealthBench Hard 2025年5月榜单)
(图为HealthBench Hard 2025年5月榜单)德适表示,不同国家和地区的诊疗指南、语言习惯、患者群体存在显著差异,任何单一评测体系都难以实现全球普适。
根据HealthBench权重规则解释,榜单核心总指标为“综合医疗推理”,当中临床诊断准确率权重最高,包括问诊逻辑、病情判断、检查用药方案、治疗建议的专业合规性等。子权重中,复杂病例推理能力是重中之重,重点观察大模型对合并症、模糊症状、罕见病、多轮复杂病史的深度推理能力。
还有两个关键规则,第一是人工医生标注打分,由多国执业医生评分,第二是,“不纳入无关指标”,解释为不看模型参数大小、推理速度、是否开源,只聚焦高难度临床医疗实战能力。

德适的DoctorBench的核心理念其实逻辑相同,官方定义为考核其 “像医生一样思考” 的临床沟通与决策能力。因此三个主要榜单围绕医学主榜单(LLM)、多模态榜单(VLM)与智能体榜单(Agent)建设,分别评测模型的文本诊疗能力、多模态理解能力,以及模拟诊疗环境中的多轮决策与工具调用能力。
但DoctorBench将 “医学事实准确” 与 “安全与风险控制” 设为具有 “一票否决权” 的红线,即任何模型若在关乎患者安全的关键问题上出现严重偏差,无论其他维度表现如何突出,均无法获得高分。
何迅表示,在榜单评测执行层面,DoctorBench采用“专业题库+人工盲审”评分制,题库为自建体系,对市场主流医疗AI产品进行全场景实测,人工审核有指标量化,保障评测结果的客观专业与公信力。
C端起量:通用VS垂直 用户怎么用?
在HealthBench Hard按季更新的榜单中,2025年8月开始出现来自中国的医疗垂直大模型,头部通用大模型产品开始出局。
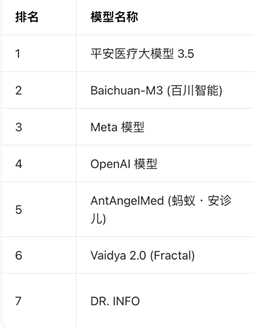 (图为HealthBench Hard 2026年4月榜单)
(图为HealthBench Hard 2026年4月榜单)何迅解释,从行业技术结构来看,通用大模型具备泛场景适配能力,但在医疗垂直细分领域的专业训练深度、知识图谱完备度不及专用医疗大模型,因此行业综合排名相对靠后。很多高性能专用医疗大模型普遍存在接口闭源、独立部署运营等特征,对大众的使用门槛较高,但专业性较强。
“从大众的应用层面看,有很多行业头部优质医疗AI智能体有开放服务端口,大众可通过名称检索直接接入服务。但可能认知度较低,也有一定专业程度要求。
有些专业术语,涉及算法参数、模型规模、架构版本等,这种不利于公众识别检索的,我们在榜单中进行了专业术语通俗释义、应用场景标签化、官方入口标注等配套解释,也包括界定了模型定位、适用领域与访问渠道,希望能降低公众获取优质医疗AI服务的信息门槛与使用成本。”
目前垂直医疗大模型已广泛应用于医院作为辅助诊疗工具。
从2025年起,“AI+医疗”已有完整政策体系,AI与医疗的深度融合是国家政策明确部署、医疗机构全面落地的确定性方向。
2025年《关于深入实施 “人工智能+” 行动的意见》将医疗健康列为七大重点领域之首,随后国家卫健委等五部门发布《关于促进和规范 “人工智能+医疗卫生” 应用发展的实施意见》,当中明确:2027年“建成高质量医疗数据集,形成临床专病垂直大模型;二级以上医院普遍开展AI辅助诊断;基层AI使用率≥40%”;2030年基层诊疗智能辅助应用基本全覆盖;“AI+医疗” 全链条服务体系成熟;居民健康管理 AI 普及率≥80%。“
市场数据显示,在医疗机构中,AI智能体覆盖诊前筛查咨询、诊中决策辅助、诊后慢病随访干预等场景。目前国内三甲医院渗透率>60%,诊断准确率95%+;二级医院渗透率约40-50%;基层医疗机构(县域/乡镇)渗透率20-30%。
何迅表示,对医生个人而言,AI可以查漏补缺。“医生难以长期记忆患者的病程数据与健康特征,AI可以永久存取,也能动态追踪指标变化。对医生的诊疗方案研判、诊疗流程优化,提升诊疗效率都有帮助。当然,患者也可以在用户端归集自己的健康数据、追踪病程等。”
目前,国内医疗资源空间分布仍有一定的结构性差距。一线及中心城市集聚大量三甲医疗机构与高端医疗人才,地级市、县域及偏远基层地区优质医疗资源仍存在供给缺口,此外,基层医务人员专业诊疗能力、业务水平也和中心城市存在明显参差。
何迅认为,在AI作为辅助工具的应用,能优化医疗资源配置,推动公共医疗服务普惠化发展,共享智慧医疗技术红利。
责任编辑:郝欣煜
热博rb88,RB88首页,
rb88随行版相关资讯:rb88游戏皇,