专题:第28届北京科博会-未来产业推介会
第28届北京科博会-未来产业推介会于2026年5月8日-9日在北京举行。合十思维(北京)科技有限公司创始人赵普出席并演讲。
以下为演讲实录:
赵普:大家好,我是合十思维的创始人赵普,我来分享一下我们公司现在正在做的事情叫功能性仿真架构+物理AI。
团队四位技术联创,我本人毕业于MIT数据科学工程与管理计算科学,导师是著名人类工程学家Max Tagmark,目前是MIT的PHD博士在读,硬件这块运控算法主要是由北京航空航天大学机器人专业课排名第一的张炎东博士负责,我跟朱老师主要是负责模型这块的,还有张超老师我们四个人负责一个模型的落地,做到物理AI的延展。
其实我们团队从2023年成立到现在一直解决这3个问题,第一个就是基于现在的LLM,包括VLN、VLM,传统机器人模型的算法无法解决没有思维意识,没有对应用物理学的认知和训练推理成本过高的逻辑,那是为什么呢?我们知道传统AI在视觉方面的训练都是基于OpenCA,包括现在的大模型,刚才大家讲了,大量的数据都是通过这样的标志训练的。
给大家举一个例子,为什么AI和机器人无法拥有对世界的认知才引发了对环境智能,包括世界模型的讨论呢?我们知道人和AI去认识世界的逻辑是不一样的,比如说一个人类的小孩要想认识世界上所有的凳子他只需要坐三把椅子,但是一个大模型要想认识世界上所有的凳子,可能得需要40万张样板,这跟原来做自驾的逻辑是一样的。
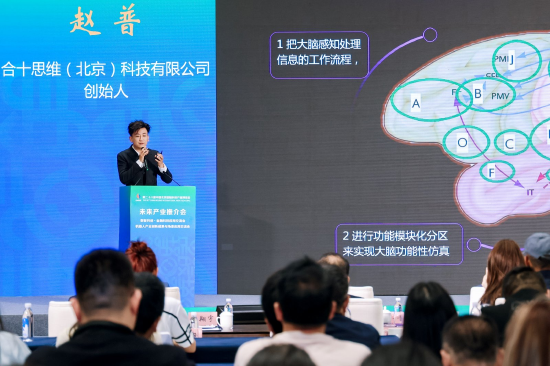
我一直在做自驾这个领域,为什么人会比AI在这方面人类自适应的智能要好很多呢?因为凳子是用来坐的,一个三岁的小孩坐了三把椅子之后就知道凳子是用来做的,同时他还可以推理出,路边的矿泉水箱子,石礅、台阶在我累的时候都可以坐,然后以我们目前AI的智力可能是没有问题,我们讲自适应的推理能力,它大概是推理不出来当一个人形机器人,当然它也没有累的概念,需要去坐椅子的时候,矿泉水箱能坐,我们是怎么做的?我们是通过人类视觉的认知通路,加上DQN回报函数推理机器人对物理世界的认知。它其实并不是世界模型的概念,世界模型还是需要训练很多的数据,于是我给它训练了一个架构,叫做BTS+SNN,2017年我在《Nature》发表一篇论文,叫做《behavior trees of robtics and AI》,就是通过人脑视觉的认知通路模拟人脑对世界工作流的一个处理的方式的过程,进而达到机器人包括AI对物理世界的理解。
我们都知道以前在FSD还没有出现的时候,还没有这么多新能源汽车的时候,我们训练一个自驾的模式,需要训练很多的数据,并且它在单一场景下可泛化的能力并不高。举个例子,一辆自驾的汽车,原来我们在自驾行业有一个术语叫没有人工就没有智能,为什么大量的数据都是通过人工去标注的?尤其只能在一个定点固定的环境里面去实现,比如说我今天在上海的道路标注了很多信息,这个车放在北京,不借助传感器这些东西就无法运行。但是对于人类来讲,我在北京开了20年车,我头一次去上海我是会开车的,并不是我要训练上海道路的信息,所以说我们通过人脑视觉认知通路把大脑分为几块区域,STS区域,我们把它分为布罗卡区和韦尔尼克区。为什么这么讲呢?所谓的大模型(Large Language Model)虽然coding了那么多的词,但是它对这个语义是不了解的。
比如说你问它今天的天气怎么样?豆包回答你今天的天气非常好,豆包回答你说今天天气非常好,天气作为一个高频出现的词,它只是一个Token,对这个句子的词义并不是有多了解。为什么?因为人脑的神经中枢里面还有另外一个区域,叫做布罗卡区域,它是理解语义的,因为人类语言有很多,比如说现在这个话筒没有声音了,我不需要说话,向导导播台一个表情,他就知道我这里肯定出现了问题,我不需要讲出来,所以我们把人脑视觉认知通路和感知通路做了一个区分,再通过跟传统的神经网络和大模型的Large Language Model Transformer的方式有区别的,从层learning rules原规则的学习,用SNN脉冲申请网络解析BTS来达到自适应的过程。
其次我们把人脑的框架给它做一个功能性的模块化的区分,我们做的仿脑的模型不是结构型仿脑,因为结构性仿脑很难,我们都知道前一段时间有一个非常经典的案例,有一个视频用结构性仿脑复刻了一个果蝇的机器人,果蝇的机器人神经元匹配了95%,我们想要把人脑的860亿个神经元完全通过结构新仿脑复刻的话,是不太现实的。因为我们大概知道,比如说我现在在演讲,我脑子里大概有860亿神经,它只有几十亿的神经元在有效工作和放电,如果860亿神经元全部连接放电的话,那个是电影《超体》里面的事情,科幻片里面的事情,我们无法复刻神经元的时候就只讲大脑的功能性,大脑的功能性在我们合作的中科院自动化所,它已经把246个分区,大脑的功能是干什么的我们已经研究很透了,但是我们不能够用现在训练AI的方式再去训练一个未来可能在机器人上面用的大脑,这个是有问题的。
我们知道之前大家都说过,搞过自驾的人再去搞机器人可能就会把机器人又搞成自驾那样,叫“皇帝的新衣”。后面为机器人大脑训练微调了11个模型,刚才给大家讲的,地区语义逻辑就分了布罗卡去和韦尔尼克区,里边有负责概念,有负责运动编码的沟区和I区负责机器人小脑的部分。包括情感类DQN的回报函数的,这个是非常重要的。
结了DeepUNet的技术,用SNN去解析,BST的脉冲神经网络,达到什么呢?机器人,或者是物理可以不用通过高质量的数据去训练它,而是通过少量的高质量数据和功能性和价值观去训练它,这个是非常大的一个突破,并且在我们的复合机器人上面完成了部署,我们知道价值很难去描述。但是刚才我举的例子,为什么人类小孩在累的时候会把路边的石礅、台阶和矿泉水箱子当成凳子去坐?在那一刻矿泉水箱子、石礅和台阶就是凳子,为什么人类能够在家里的时候,比如说大家都拆过快递吧,现在拆快递没有壁纸到,我就特别丝滑的拿起钥匙、圆珠笔把胶带划开,但是如果机器人这样的话,一个人形机器人不仅现在不会拆快递,如果你给它训练拿壁纸刀拆快递,它是不会想着拿指甲刀、剪刀和圆珠笔去拆开的,为什么?因为在人类的底层逻辑认知里面,钥匙、指甲刀、圆珠笔都有一个底层的属性就是BTS,是坚硬的。这个会场不能够抽烟,现在想抽烟,没有烟灰缸,我可以拿一个水杯,水杯和烟灰缸都是容器,这个就是BTS里面的作用。这个物体在这一刻它的价值是什么?我们不需要再通过外形训练它。于是在我们的BTS+SNN脉冲神经网络前项通路和Transformer有一个最大的区别就是我们在前项通路每一层加了一个反馈通路,让它在物理世界中有因果性和延续性,并且在任务的延续性之间有了记忆。
最后我们会发现,这11个模型里边,我们真正在执行任务的时候,只对应用到了其中的五个模型,就是你的各种的传感器对应我应该执行任务的本身,其实这个我觉得有点玄学,就像般若波罗蜜心经里面讲的,眼、耳、鼻、舌、身、意对应的是什么?就是色、声、香、味、触。这个物理世界里面本来应该有的这些东西来发生了这一切。最后我们再把大脑理解完的东西变成输入信号,让小脑变成它的控制信号,我现在给机器人讲,你去给我拿这个箱子,它听到这个话之后先得把箱子这种物体转化为眼中的坐标,再把这个语义理解完,然后由大脑给小脑发送任务,由这个任务驱动机器人本体控制器,变成动作,是这样一个流程,这是我们大概的成本,就不多说了。
目前我们公司成立了大概3年,我们在2024年、2025年的时候,把我们仿脑的模型已经可以跑在一张3090和4090显卡上面,轻量化的大概有8B,重一点的可能有30B,8B和30B的模型跑在复合机器人上面,2025年实现了8300万的收入,今年一季度的收入大概是在3400万,大家知道人形机器人你想要让它商业化很难。
这个是我们实地的视频,大家可以看,搭载了仿脑系统物理AI硬件,包括复合型的机器人,这个是和海淀市政合作的,已经在海淀公园公共卫生间操作了。过去这种清洁机器人大家见到的也很多,最大的弊端是,我遇到一个不同的清洁场景,我就是需要训练我就需要建图,比如说对一个清洁工阿姨来讲,我今天在海淀市政公共厕所里面打扫卫生间,明天我去了首都机场打扫卫生间,我不需要再训练了。但是对于清洁机器人来讲,你把这个机器人搬到,假设不是用的仿脑的模型,只是在海淀这个地方在工作,它换了同样的一个场景,又需要理解环境本身,就是非常的复杂。
我们不能够说对机器人训练不去反思人类在这个社会兼容工作的方式,我们说大家买一个扫地机器人在家里边第一件事就是打开箱子,然后把所有卧室门打开建图,它才开始扫地,今天你们家里边来了一个保洁阿姨,你说把厨房冰箱打开一下。保洁阿姨说对不起,我没来过你们家,你需要把你们家所有房门打开,我建完图才知道冰箱在厨房,这件事情发生在机器人身上,按现在的训练方法非常搞笑。当然现在还有另外一种技术路线就是无图导航,这个都是可以实现的,但是在BTS+SNN的行为数的仿脑的模型里面,我们就会把一些5处方的因果关系逻辑就是在里边有冰箱、设施来给它做一个强绑定。
这个就是我们这个月在5月16号即将发布的全尺寸的第三代人形机器人,做了哪些改变呢?在硬件方面,我们既考虑了骨骼的刚性,又考虑了肌肉的柔性,这个也是我们公司的康博士和张博士带领我们去做的。第二我们没有用到现在主流的人形机器人厂商,比如说像刚刚陈总介绍的松延动力和宇树和优必选用的踝策略。我们看到目前人形机器人脚底部是一个平板,我们用到了髋策略,是符合人体运动工程学的,用核心力量去控制,因为人形机器人也是仿人形做,虽然我们看它现在跑得很快,运动得很厉害,那是因为你把关节的电机扭矩加大,再通过MCP去控制。
这个是弹簧负载模型,这个是我们上上个月已经实验了那个腿部弹性力量和弹性监督都做得非常好,并且在前脚掌有一个欠缺的自由度,这个是我们全新的结构,目前我们也是自研了电机,但是减速器没有自研,说到最关键的地方,我们讲到现在机器人最关键的问题就是数据。为什么仿脑可以可以通过少量的数据,甚至是低成本数据,或者是零数据训练一个比较简单,或者未来比较复杂的任务呢?
我们知道现在机器人的技术除了走路这一块,剩下都是从传统PLC工业机器人落地过来的。比如说即便你需要一个动捕手套的,我还得配一个六轴腕或者是七轴的机械臂,原来原本的就是中间exploration的基础上,我们给它加入了仿脑神经网络,让机器人先理解,然后再驱动。为什么呢?因为现在即便是做得再好的机器人,比如说特斯拉的optimus,像波士顿的Atlas,我们只在运动的层面去考虑这个机器人动得好不好?当它执行的时候,我们在机器人大会也看到非常混乱,一塌糊涂,就比如说拿什么样的东西也好,分拣什么样的物体也好?因为什么?因为这个东西分拣的是水果还是什么东西?那个东西在机器人眼中如果你不给它加入这个东西到底是什么?意味着什么。
比如说它现在拿一瓶水,拿水的动作意味着什么?那瓶水在它眼睛就是一个三维点云,我只需要在物体坐标的三维点云和基坐标之间完成转化就行了,但是人类的一些运动属性是天生的,我渴了我就去喝水,但是这种逻辑我们现在不能以偏概全把它移植到AI上面。最后,我们先认知完了再用运动算法控制机械臂本身,再把运动过程中你失败和成功的数据拿回来,放到第四步训练,然后形成一个闭环,叫做self improvenment,自改进训练环节。
其实和人类的经验一样,一个保洁阿姨干得很好,她不是一开始就干得这么好,一定是经历了很多工作才干得这么好。我们现在对机器人期望值很高,但是我希望让子弹飞一会儿,它一定是有不同的解决路径,是一个全行业的问题,而不是VLN好、VLA好,或者是世界模型好,或者是什么好,或者仿脑好,不是这样的,我们提出了一个方法,并且今年也会在《Nature》上面再去发一篇论文。
这个其实就是合十思维想做的事情,我们想要做一个具身智能操作系统,以后给物理AI(Physical AI)供系统,想做一家类似于像Microsoft这样的公司,大家知道电脑有很多,有联想、华为、华硕,但是操作系统一定是Windows,当然这个远景很大,目前是我们公司的愿景,这是我们对物理AI的理解。这个也是我们在宇树的G1上面把仿脑模型嵌入以后,实现非盲走训练的过程。我们知道过去人形机器人到台阶是用脚尖踢,通过平衡来控制,但是它现在看到楼梯之后会迈腿。它有深度视觉,它会迈腿,这个完全是用的我们的仿脑模型,我们在整个与G1上面也完成了用语言控制让它完成动作,甚至做一些工作的事例,当然这个没有声音也没有关系。
这个是仿脑模型的检测报告,这是目前公司成立以来拿到的专利和软著,比较有技术含量的就是一种神经形态类脑的系统,就是刚刚给大家介绍的仿脑的AI。
我们的类脑模型也向中国人工智能奠基人张钹做了汇报,目前公司是国高新和专精特新,也是中国信通院的可信开源项目组织,我们今年会把仿脑的模型开源。目前公司是融了二轮,今天的汇报就到这里,谢谢大家!
新浪声明:所有会议实录均为现场速记整理,未经演讲者审阅,新浪网登载此文出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。
责任编辑:梁斌 SF055
头玩app官网,球盟会,
头号玩家在线下载相关资讯:球盟会登录,