作者 | 赵芷姗
编辑 | 周伟鹏
继DeepSeek宣布永久降价后,又一家国产大模型宣布降价了。
5月27日凌晨,小米宣布MiMo-V2.5系列API永久降价,最高降幅达99%,且不再区分输入长度。
同时对Token Plan计费体系进行优化,同样的套餐价格,用量提升至原来的5-8倍。
所有已订阅Token Plan且在有效期内的用户,从今天0点起全部重置按照新计费规则执行。
小米创始人雷军,随后在微博也转发了这条降价消息。

国产模型降成白菜价
对比国外模型价格优势明显
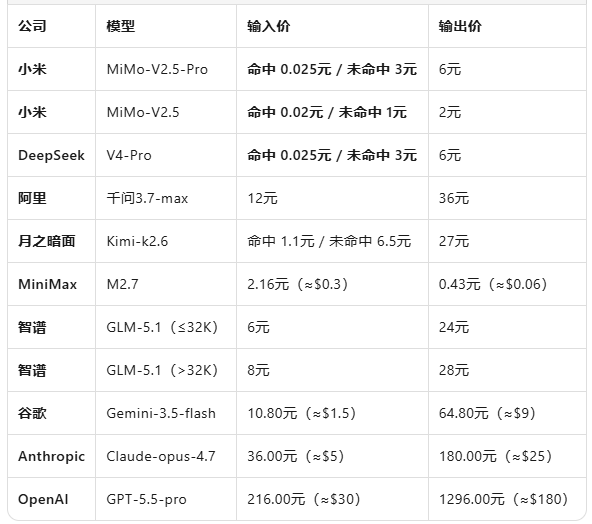
公告显示,MiMo-V2.5-Pro调价后,输入缓存命中价格降至0.025元/百万tokens,输入未命中缓存3元/百万tokens,输出6元/百万tokens。

它跟几天前DeepSeek-V4-Pro宣布降价后的价格刚好一致。
自今年年以来,国内头部大模型厂商已掀起一轮持续、全面的降价潮,价格堪称“白菜价”。
按照每百万tokens的单价,Kimi-k2.6缓存命中输入价1.1元,缓存未命中输入价6.5元,输出价27元。
其他模型价格具体如下图:
而对比海外主流模型,国产大模型的价格优势堪称碾压级。
MiMo-V2.5-Pro的输入价格仅为Claude-opus-4.7的三十六分之一,输出价格更是达到九十分之一。
在这样巨大的价格差下,一些外国码农都受不了,反向代购中国大模型。

硬件和云在暴涨,token在暴跌
利润到底从哪来?
极具反差的是,当国内模型token降价的同时,底层的硬件、云算力成本却在持续暴涨。
全球AI算力、云服务、硬件设备全面进入涨价周期,彻底终结了云计算二十年“只降不升”的行业惯例。
国内阿里云、腾讯云、百度智能云三大头部厂商,先后上调AI算力产品价格,涨幅区间5%-34%。
同时,高性能存储、算力租赁、服务器整机价格同步上涨,英伟达H100 GPU年租赁价格涨幅近40%,部分腾讯云AI算力服务涨幅更是高达400%,海外AWS、谷歌云同步跟进涨价,全球AI底层算力成本全面走高。
按理说,上游成本上涨必然带动下游模型涨价,但国产大模型却反向降价,它们的利润都从哪里来?
答案藏在推理效率里。
大模型API的成本结构正在发生质变。过去,成本大头是模型训练和参数存储;现在,随着模型开源、蒸馏技术成熟,训练成本被摊薄,真正的战场转移到了推理环节:如何让每一次API调用的算力消耗更低、吞吐更高、延迟更短。
尤其是在长上下文、Agent、多轮对话场景下,真正的吞金兽是KV Cache。
可以把它理解为模型推理时对上下文的“记忆”。上下文越长,缓存就越庞大,吃掉的显存也越恐怖。很多长上下文模型定价高昂,本质上不是因为“更聪明”,而是缓存成本居高不下。
小米这次的技术攻坚,正是冲着这个痛点去的。
DeepSeek V4系列之所以敢定价0.025元,也是因为在推理框架、缓存系统和集群调度上做了深度优化。
硬件贵了,但单位token消耗的算力下降得更快。
另外,薄利多销的逻辑在这里依然有效。模型降价后,开发者不再吝啬调用量,Agent框架、多轮对话、长文档分析的消耗量会指数级增长。

中美大模型之战
谁是赢家
于是到这里就会产生一个问题:
当中国大模型价格只是美国的顶尖模型十分之一,而功能却能达到百分之八九十,那么这场模型大战,中国凭什么输?
过去两年里,业界普遍有一种担忧:中国在基础模型能力上始终落后OpenAI和Anthropic半步,从GPT-4到Claude 3.5再到GPT-5.5,每次发布都在拉大差距。这种焦虑是真实的。
但价格带来的强劲竞争力,也是客观的。
企业在采购AI服务时,决策公式从来不是选最强的,而是选性价比最高的;当token便宜到忽略不计时,开发者不用再精打细算,可以大胆进行设计,从而催生出独有的应用生态。
国产大模型厂商正在把大模型做成新时代的水电煤:便宜、稳定、随取随用。
按照商业发展的规律,最后赢的,往往不是技术最强的那个,而是让技术变得最便宜、最普及的那个。
中国大模型显然已经走在了这条路上。
米兰体育官网,多乐游戏注册,
milan.com相关资讯:多乐游戏,